Python Plugin Development¤
Introduction¤
Python plugins are small software projects which extend the functionality of eccenca Corporate Memory. They have its own release cycle and are not included in the main software. Python plugins can can be installed and un-installed during runtime.
In order to support the development of python plugins, we published a base package as well as a project template. Please have a look at these projects to get started.
This page gives an overview on the concepts you need to understand, when developing plugins.
Plugin Types¤
The following plugin types are defined.
Workflow Plugins¤
A workflow plugin implements a new operator (task) that can be used within a workflow. A workflow plugin may accept an arbitrary list of inputs and optionally returns a single output.
The lifecycle of a workflow plugin is as follows:
- The plugin will be instantiated once the workflow execution reaches the respective plugin.
- The
executefunction is called, and get the results of the ingoing operators as input. - The output is forwarded to the next subsequent operator.
The following depiction shows a task of the plugin My Workflow Plugin. The task has two connected ingoing tasks and one connected outgoing task.
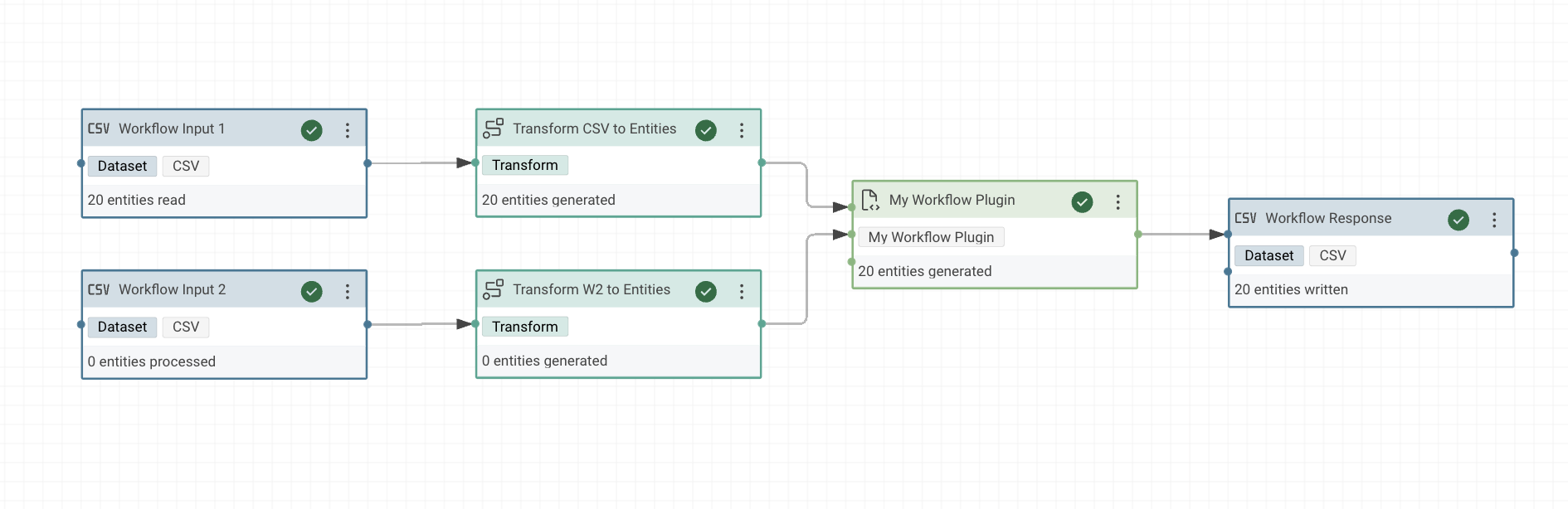
The corresponding source code is listed below:
from typing import Sequence
from cmem_plugin_base.dataintegration.context import ExecutionContext
from cmem_plugin_base.dataintegration.description import PluginParameter, Plugin
from cmem_plugin_base.dataintegration.entity import Entities
from cmem_plugin_base.dataintegration.plugins import WorkflowPlugin
@Plugin(label="My Workflow Plugin")
class MyWorkflowPlugin(WorkflowPlugin):
"""My Workflow Plugin"""
def execute(
self, inputs: Sequence[Entities], context: ExecutionContext
) -> Entities:
return inputs[0]
Transform Plugins¤
A transform plugin can be used in transform and linking rules. It accepts an arbitrary number of inputs and returns an output. Each input as well as the output consists of a sequence of values.
The following depictions shows a value transformation which uses the My Transform Plugin plugin. The plugin splits the input strings and just forwards the last word.
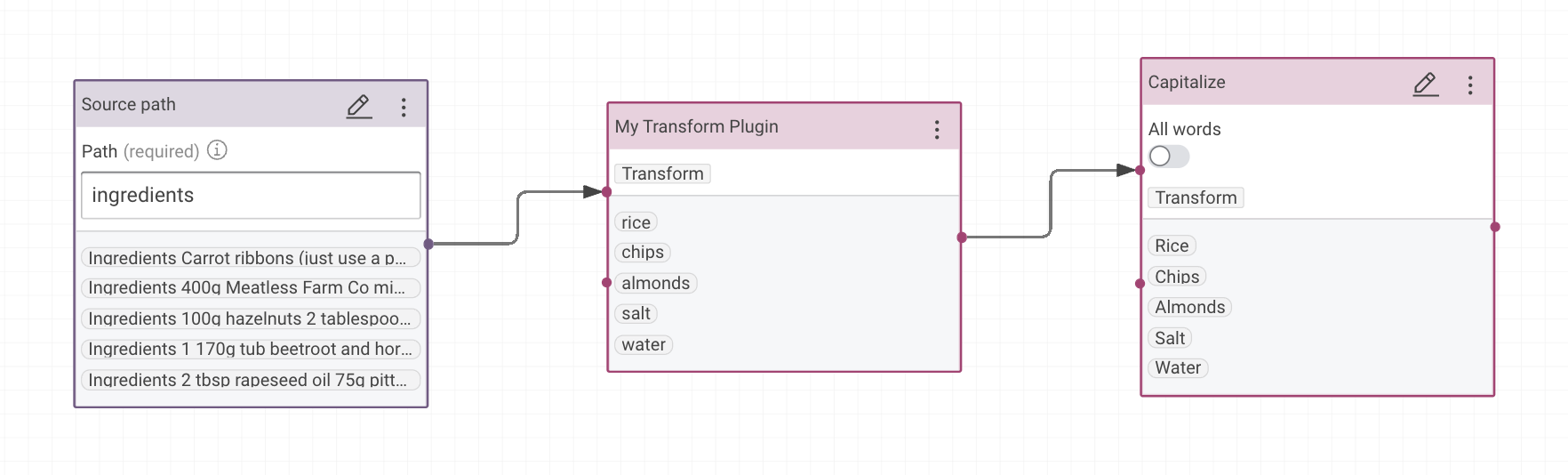
The corresponding code of the depicted plugin is shown below.
from typing import Sequence
from cmem_plugin_base.dataintegration.description import PluginParameter, Plugin
from cmem_plugin_base.dataintegration.plugins import TransformPlugin
@Plugin(label="My Transform Plugin")
class MyTransformPlugin(TransformPlugin):
"""My Transform Plugin"""
def transform(self, inputs: Sequence[Sequence[str]]) -> Sequence[str]:
for item in inputs:
return item[0].split(" ")[-1]
Context Objects¤
The cmem-plugin-base package describes context objects, which are passed to the plugin depending on the executed method.
| Class | Description |
|---|---|
SystemContext |
Passed into methods to request general system information. |
UserContext |
Passed into methods that are triggered by a user interaction. |
TaskContext |
Passed into objects that are part of a DataIntegration task/project. |
ExecutionReport |
Workflow operators may generate execution reports. An execution report holds basic information and various statistics about the operator execution. |
ReportContext |
Passed into workflow plugins that may generate a report during execution. |
PluginContext |
Combines context objects that are available during plugin creation or update. |
ExecutionContext |
Combines context objects that are available during plugin execution. |
Entities¤
An entity is a structure to describe data objects, which are passed around in workflows from one task to another task.
An entity is identified by an uri and holds values, which is a sequence of string sequences (= a list of multi value fields).
Multiple entities are handled as entities objects, which have an attached schema to it.
A schema contains of path descriptions and is identified by a type_uri.
The following depiction shows these terms and their relationships. (1)
- The concrete implementation details of entities can be seen in the entity module of the cmem-plugin-base package.
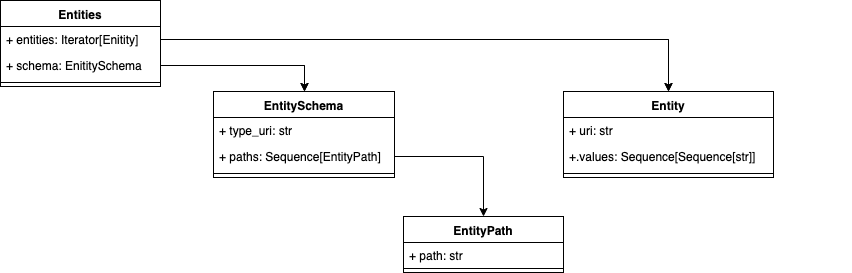
| Class | Description |
|---|---|
Entities |
Holds a collection of entities and their schema |
Entity |
An Entity can represent an instance of any given concept. |
EntitySchema |
An entity schema that represents the type of uri and list of paths |
EntityPath |
A path in a schema |
Producing Entities¤
The following section shows the source code of a Produce Entities plugin, which is commented below.
Let’s understand code:
- State about the plugin and add necessary description. (#17-27)
- Define the parameters of the plugin, here two parameters are defined where one accepts
rowsand othercolumns. (#24-41) - Intialise the parameters of the plugin. In addition to this, you can validate and raise exceptions from
init(). (#46-54) - To return Entities we have to create list of
entitiesand itsschema. As a first step, declare entities has an empty list. (#62) - As you know, each
Entityshould have aURIand can have sequence ofvalues. Here, list of entities are created with a random UUID based on rows and values are created based on columns. After each entity is created it is appended to the entities list. (#64-78) - To generate
schemawhich is of typeEntitySchema, should have atype_uriand sequence ofpaths, define an empty list of paths. (#79) - Based on the columns, each unique path is appended to the paths list. Once all paths are added, the schema is updated respectively with
type_uriandpaths. (#80-86) - Once entities and the schema is generated successfully you can return it. (#101)
- Update plugin logs using
PluginLoggerwhich is available has a default logger. (#87-91) - To make your plugin more user friendly you can use Context API
report.update()to update the workflow report. (#91-100)
Consuming Entities¤
Consuming entities in a workflow plugin means that you process at least one entities object from the inputs list.
The following code shows a plugin, which loops through all inputs and counts all entities and its values.
Let’s understand code:
inputsfrom the workflow are sequence ofEntities, each item from input has list of entities and each entity has its values. (#22-26)- One end of values count, workflow reports get updated with total number of entities and values as summary. (#27-37)
Configuration¤
Plugins can have an application wide configuration, which can not be changed on runtime and is the same of all instances of this plugin.
This plugin configuration is provided as self.config PluginConfig object to the plugin.
The get method of this object returns a JSON string of the configuration.
Plugin configurations use the plugin_id as a config path in the dataintegration.conf.
Logging¤
Logging should be done with the PluginLogger, which is available as self.log in all plugins.
On runtime, this logger will be replaced with a JVM based logging function, in order to feed the plugin logs into the normal DataIntegration log stream.
This JVM based logger will prefix all plugin logs with plugins.python.<plugin id>.