Build the Knowledge Graph from indicators of compromise rules, like Hayabusa and Sigma rules¤
Introduction¤
There are a lot of sources to download the indicators of compromise rules to detect a possible future incident.
There are rules for Host-based intrusion detection systems (HIDS) with Hayabusa/Sigma, for example, and Network intrusion detection systems (NIDS) with Suricata/Zeek for example.
Here, we are working with the Hayabusa/Sigma rules available via GitHub:
The problem of interoperability, here, is the YAML format of files, their random position in their folders in their Github projets. Moreover, the same rule can exist in different projects but in this tutorial, we will not fix this problem and we consider the IRI rule is their Web address. In Corporate Memory, we would fix that with the Linked Tool, we will study this tool in a next part of this tutorial.
To build this knowledge graph of rules, we need to:
- Create a JSON dataset with all rules
- Build the transformer of a JSON rule to RDF
- Build a workflow to insert each rule in an unique knowledge graph
- Use this workflow in CMEMC to import automatically all rules
Import the JSON datasets¤
The YAML syntax is used to define each rule and there is one file by rule.
Corporate Memory doesn’t support YAML (for the moment) but you can convert the files in JSON with this bash where you need to install git and yq.
Moreover, we use yq to add the field rulePath in each file with their paths in their repositories to have the possibility to rebuild their positions on the Web and so allowing the analyst to click directly on this link to read the details and may be, modify this rule.
At the end of this bash, you will have a tree of JSON files and we will apply a workflow on each file.
Tip
Don’t forget to replace the final folder before using this bash.
#!/bin/bash -x
output_dir_rules=/home/karima/datasets/rules
mkdir -p ${output_dir_rules}
cd ${output_dir_rules}
git clone --depth 1 https://github.com/Yamato-Security/hayabusa-rules
git clone --depth 1 https://github.com/SigmaHQ/sigma
for file in $(find . -name '*.yml'); do
[ -f "$file" ] || break
yq ".rulePath = \"${file}\"" -o=json $file > ${file}.json
done
We can test this script:
cd ~/git/tutorial-how-to-link-ids-to-osint/docs/build/tutorial-how-to-link-ids-to-osint/lift-data-from-YAML-data-of-hayabusa-sigma
chmod +x importRules.sh
./importRules.sh
For example, the file proc_creation_win_bcdedit_boot_conf_tamper.yml will become this JSON file:
{
"title": "Boot Configuration Tampering Via Bcdedit.EXE",
"id": "1444443e-6757-43e4-9ea4-c8fc705f79a2",
"status": "stable",
"description": "Detects the use of the bcdedit command to tamper with the boot configuration data. This technique is often times used by malware or attackers as a destructive way before launching ransomware.",
"references": [
"https://github.com/redcanaryco/atomic-red-team/blob/f339e7da7d05f6057fdfcdd3742bfcf365fee2a9/atomics/T1490/T1490.md",
"https://eqllib.readthedocs.io/en/latest/analytics/c4732632-9c1d-4980-9fa8-1d98c93f918e.html"
],
...
"tags": [
"attack.impact",
"attack.t1490"
],
...
"level": "high",
"rulePath": "./sigma/rules/windows/process_creation/proc_creation_win_bcdedit_boot_conf_tamper.yml"
}
Create the knowledge graph¤
The collected rules are from Sigma and Hayabusa repositories. Hayabusa “are trying to make this rules as close to sigma rules as possible”. In your use case, we need properties defined by Sigma and which also exist in Hayabusa rules. The day where there will be a official RDF vocabulary to define a rule, we will use it. Waiting, your minimal vocabulary is “defined” here: https://github.com/SigmaHQ/sigma-specification/blob/main/Sigma_specification.md#. We use this address for the prefix of your RDF vocabulary for your use case.
The filename of the same rule between repositories does not change. So, we are making the IRI of rules with their filename and a arbitrary IRI, like “http://example.com/rule/”. However, we want to give the possibility to open the original YAML rule directly via SPLUNK, so we add the property rdfs:isDefinedBy to associate the rule Web URLs to a rule.
We will not use the guid id or Web address of the rule in its IRI because rules are often duplicate between the repositories and the filename and the title seem to be the used IDs of rules in Splunk and not the guid id.
This new transformer are building the following RDF model for your use case:
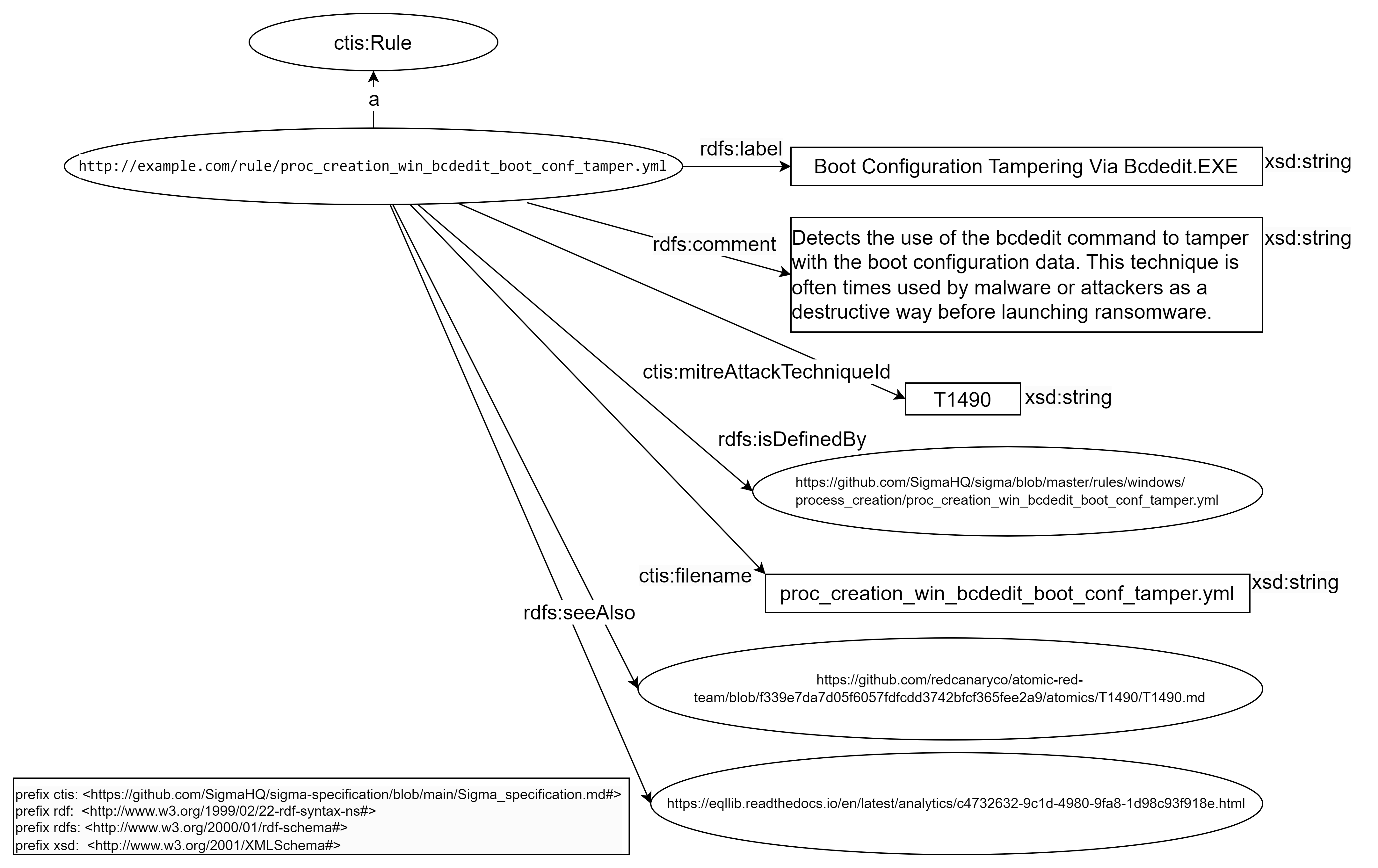
-
Create a new project to build the knowledge graph of “Rules Hayabusa Sigma”
-
In this project, create a RDF dataset “Rules Hayabusa Sigma” in Corporate Memory for all rules with the named graph:
http://example.com/rule -
Create a JSON dataset “Rule example (JSON)” in Corporate Memory with one example of rule:
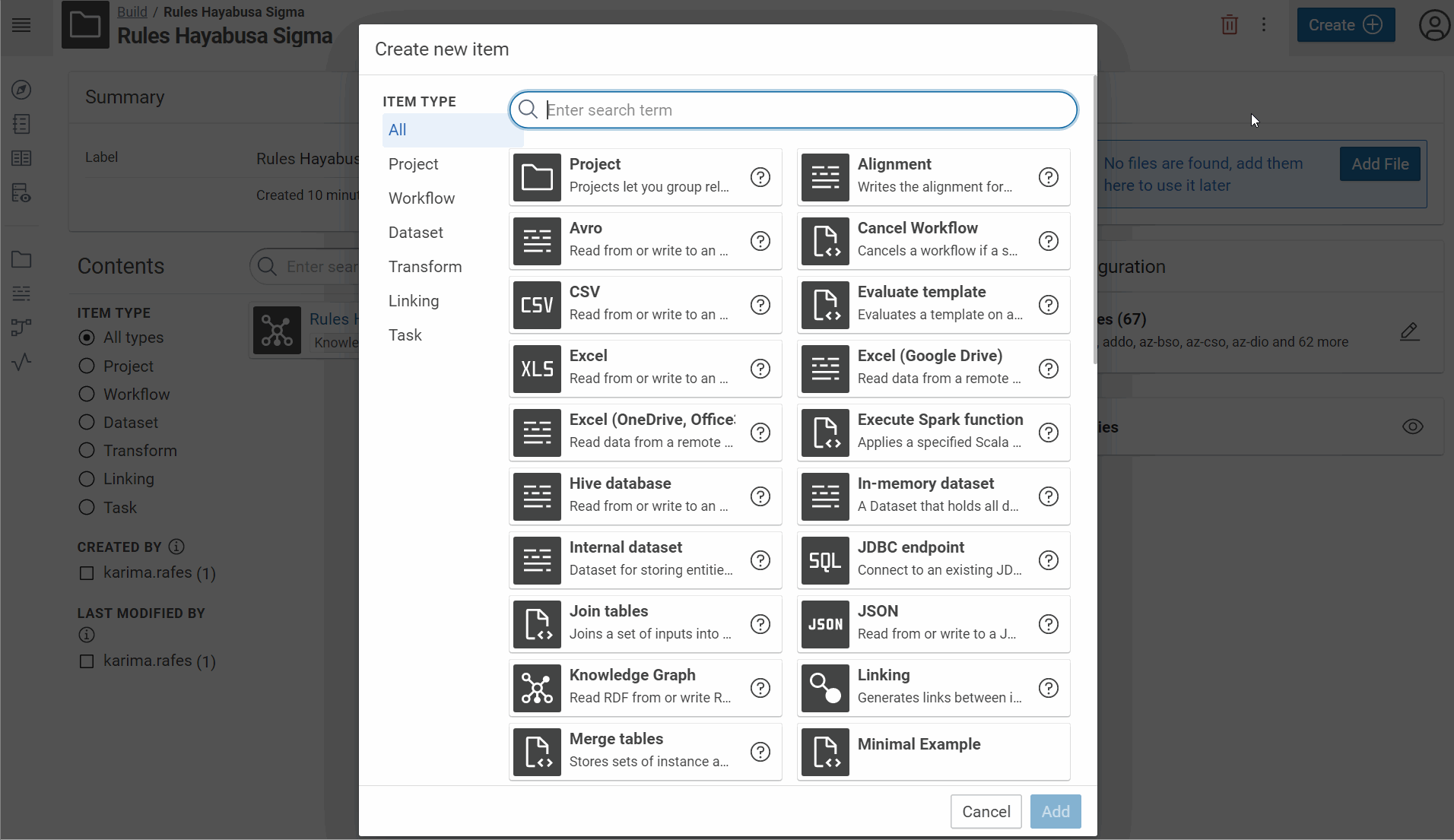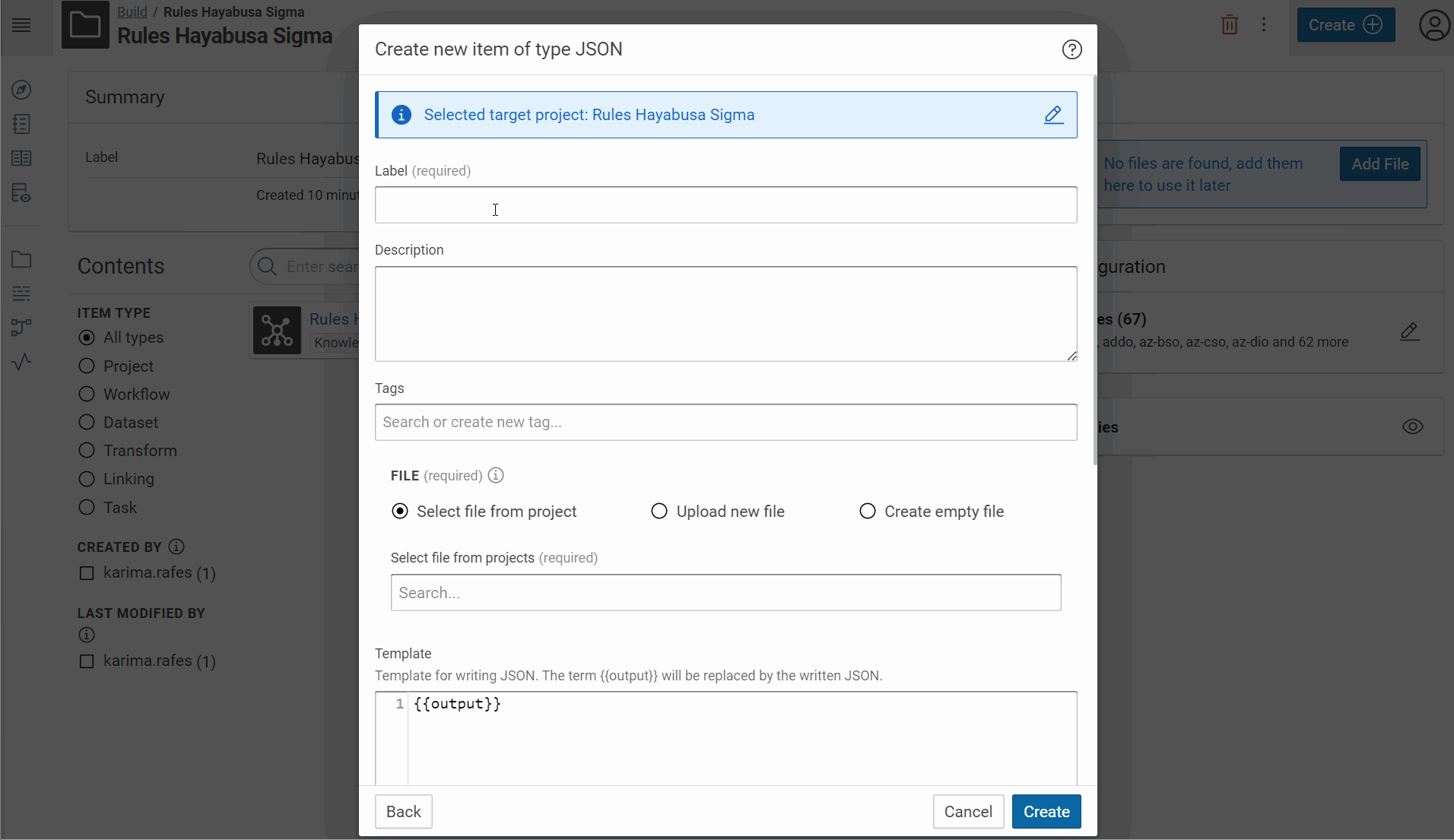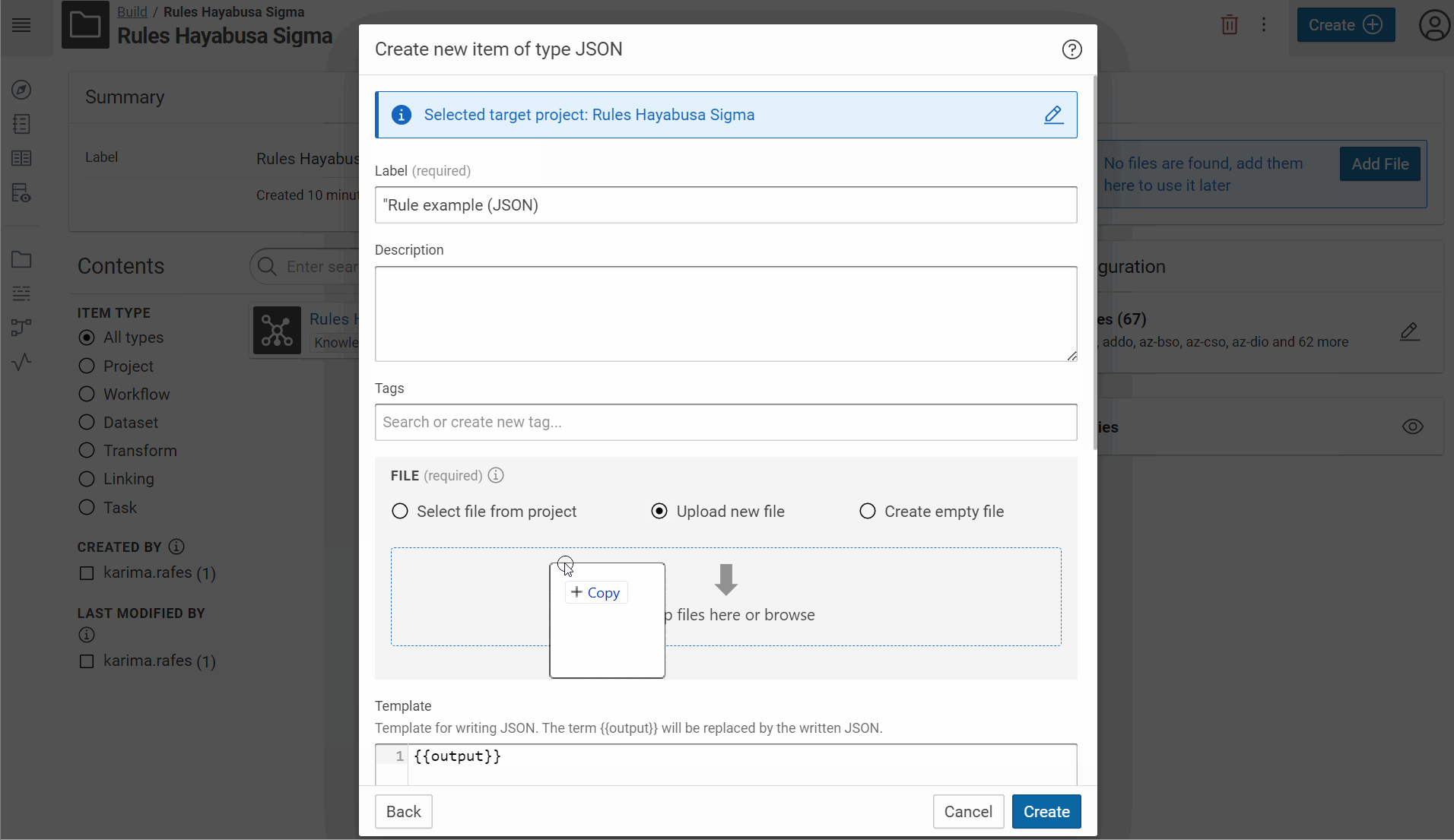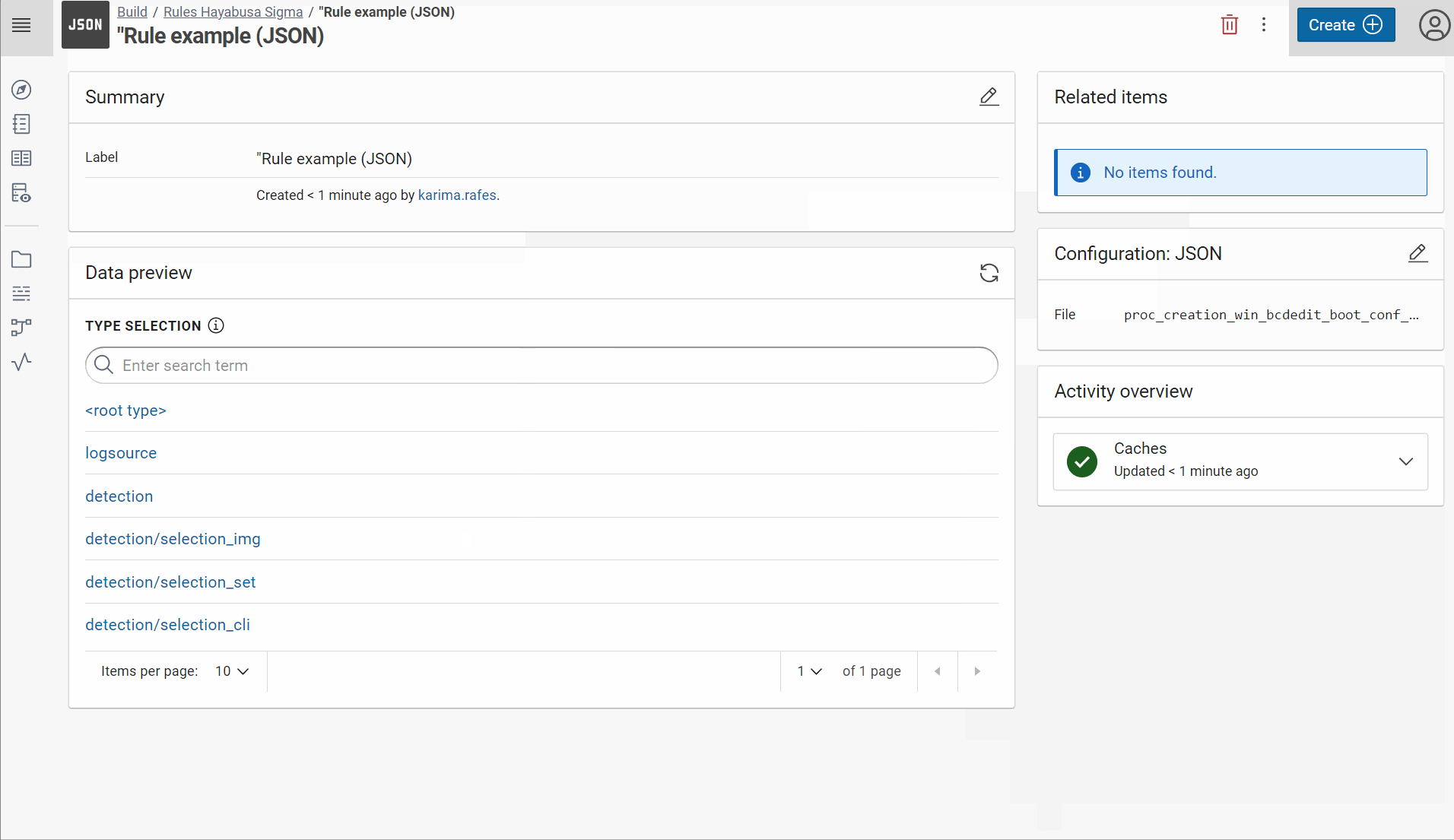
-
Create the prefix of your vocabulary:
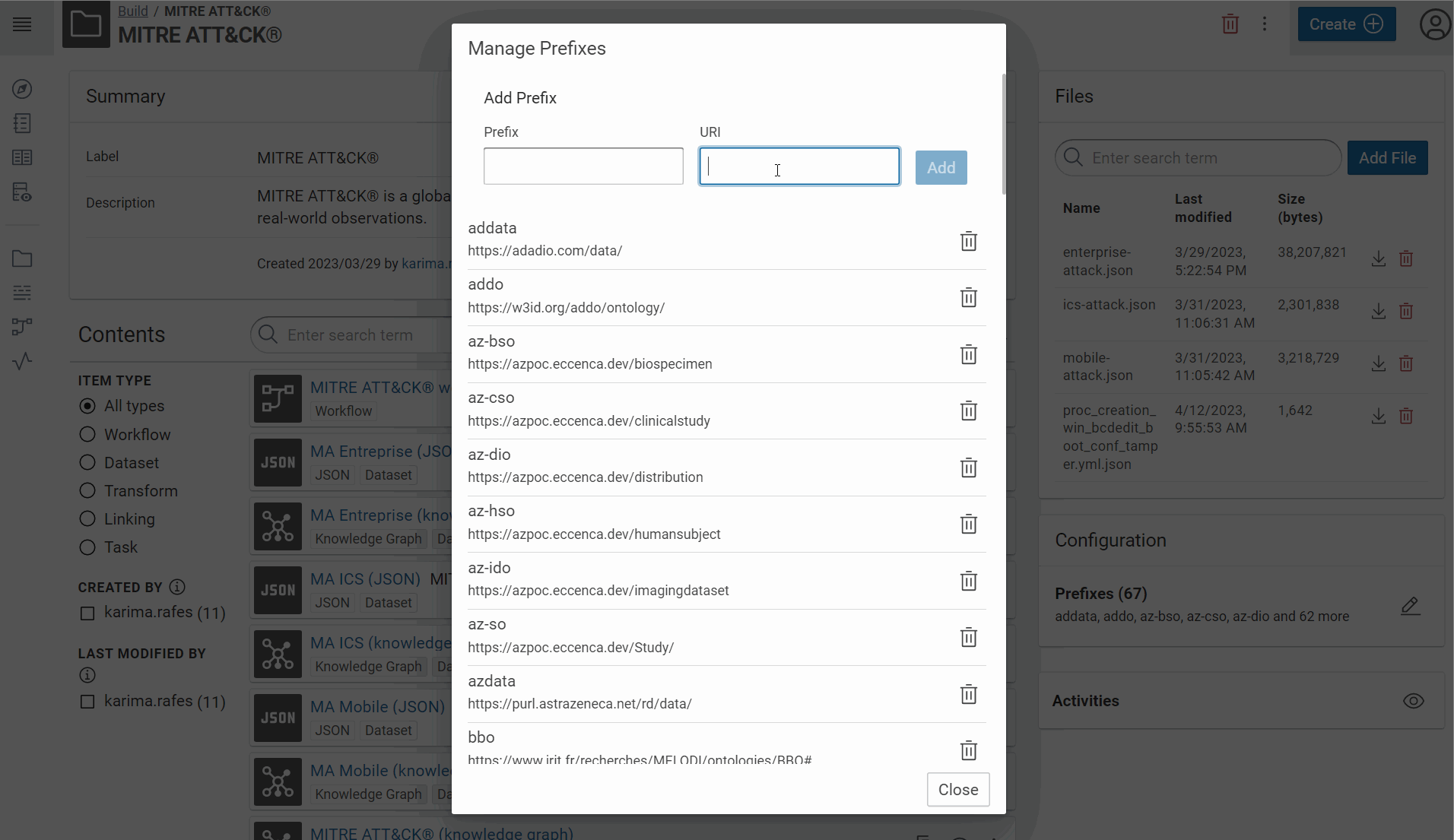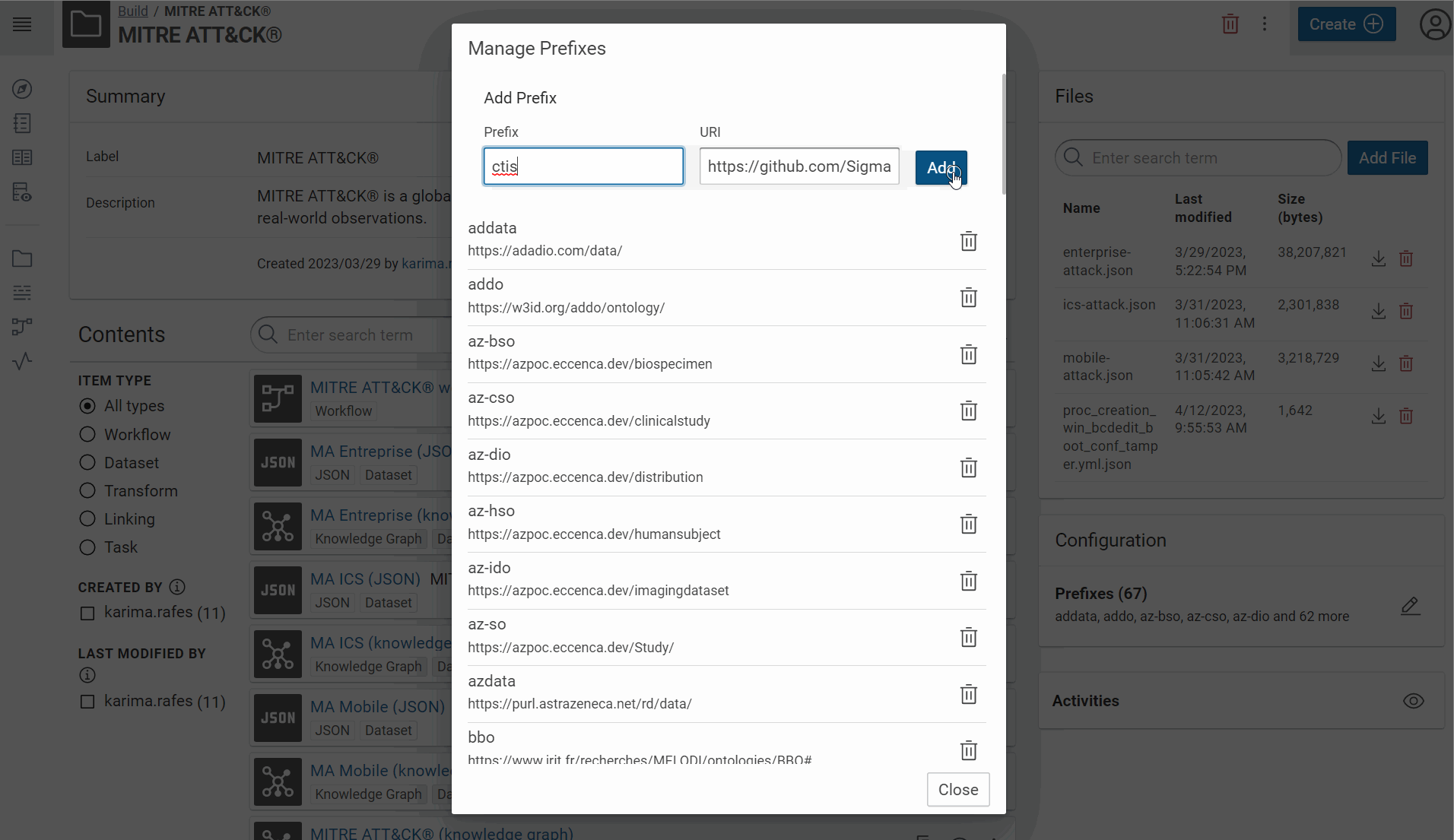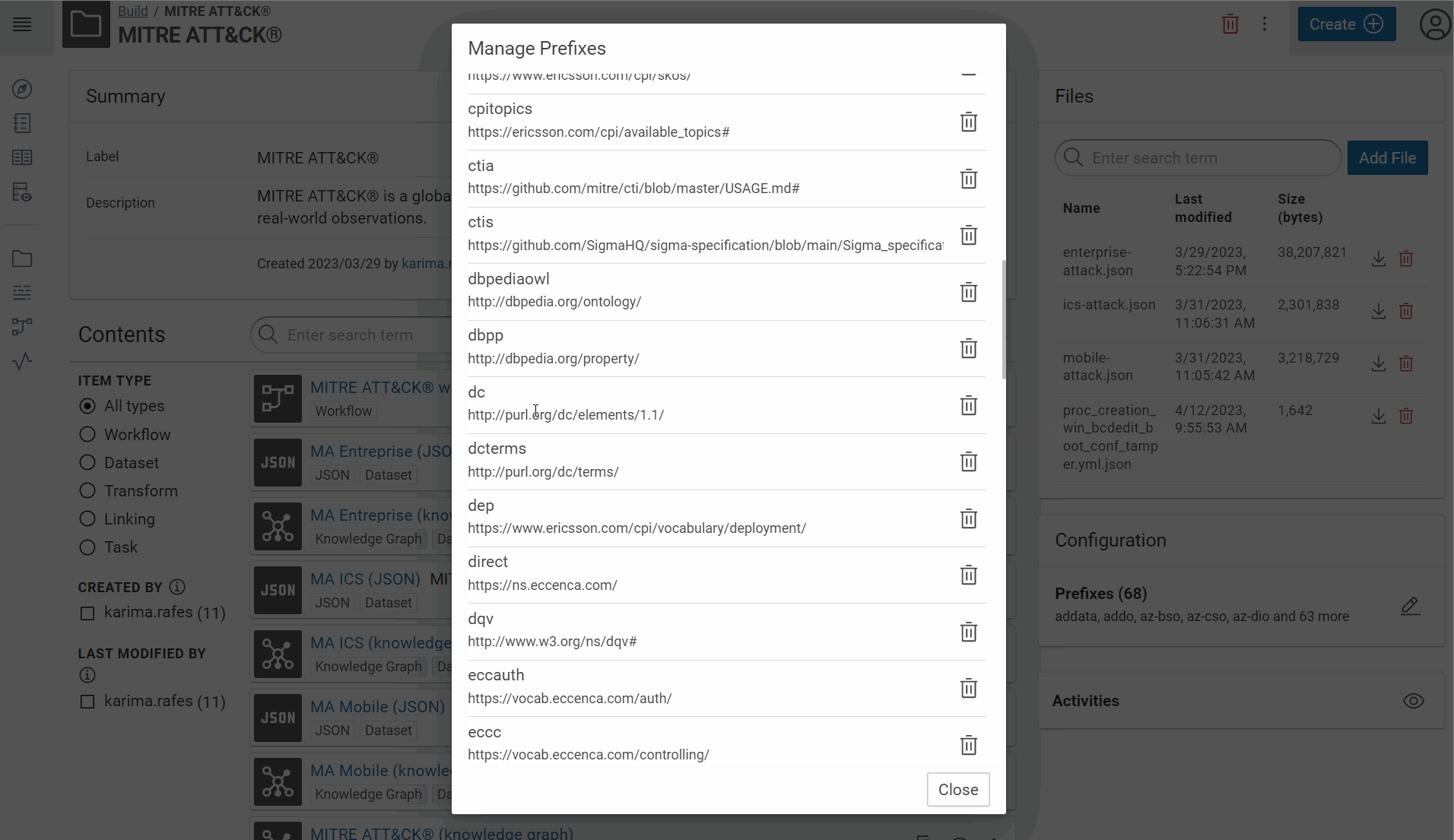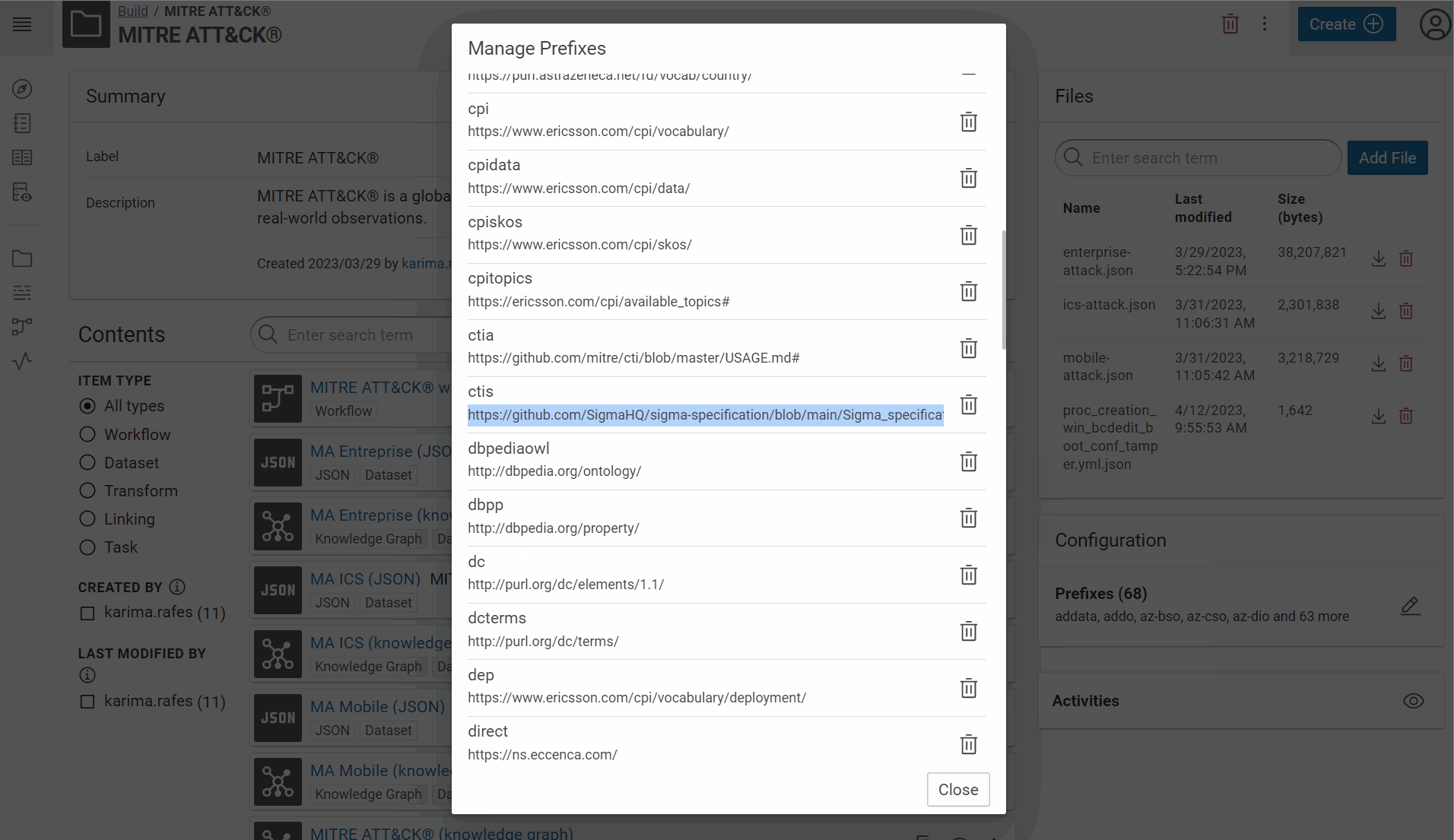
-
Create the transformer for “SIGMA Hayabusa rule” to build this RDF model.
Rule object:
-
type:
ctis:Rule -
IRI: concatenation of “http://example.com/rule/” with the result of this regular expression
^.*?([^\/]*)$on the rule path
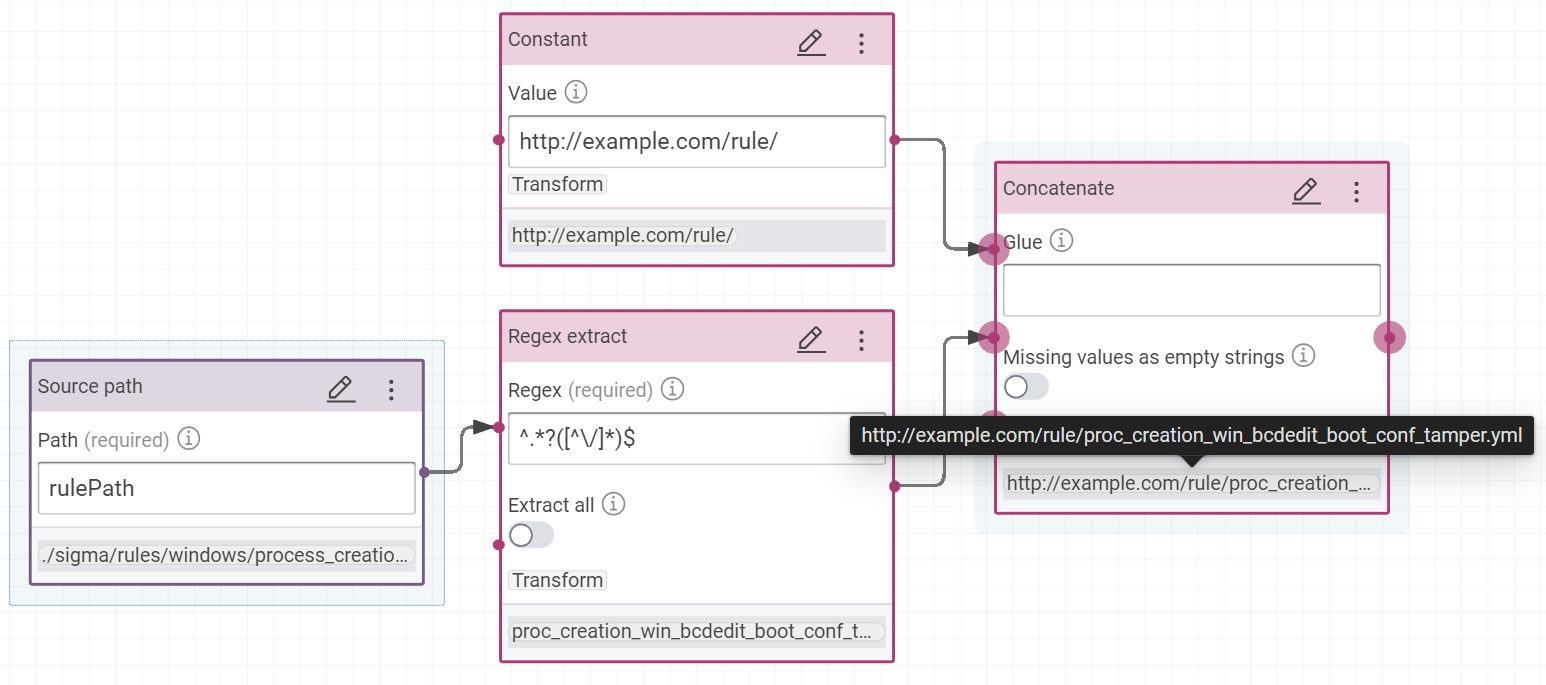
- property
ctis:filenamewith the result of this regular expression^.*?([^\/]*)$on the value pathrulePath - property
rdfs:labelwith the value pathtitle - property
rdfs:commentwith the value pathdescription - property
rdfs:seeAlsowith the value pathreferences - property
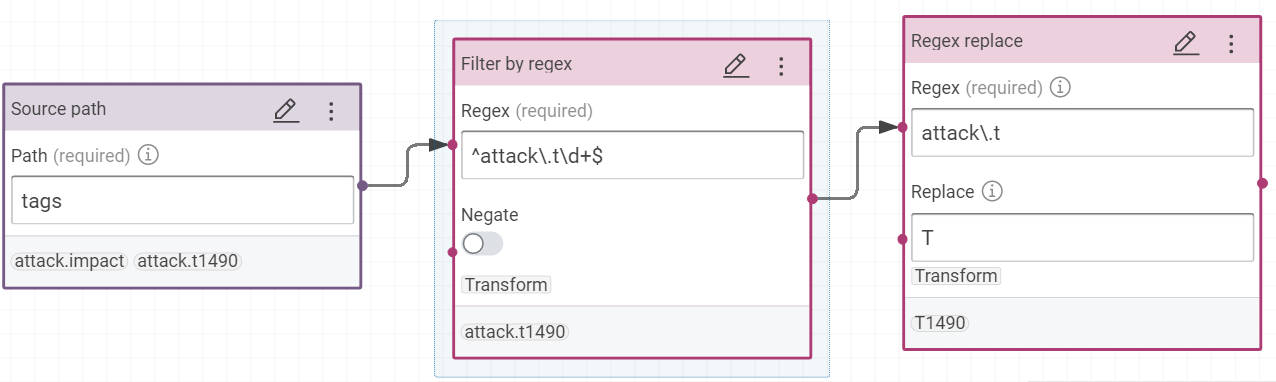
ctis:mitreAttackTechniqueIdis building with this formula with the value pathtags- Filter by regex:
^attack\.t\d+$ - Regex replace
attack\.tbyT
- Filter by regex:
- property
rdfs:isDefinedByon the value pathrulePathis building with this formula to link the rules to their Web addresses.- Add two “Regex replace”
- replace
\./hayabusa-rules/byhttps://github.com/Yamato-Security/hayabusa-rules/blob/main/ - replace
\./sigma/byhttps://github.com/SigmaHQ/sigma/blob/master/
- replace
- Add two “Regex replace”
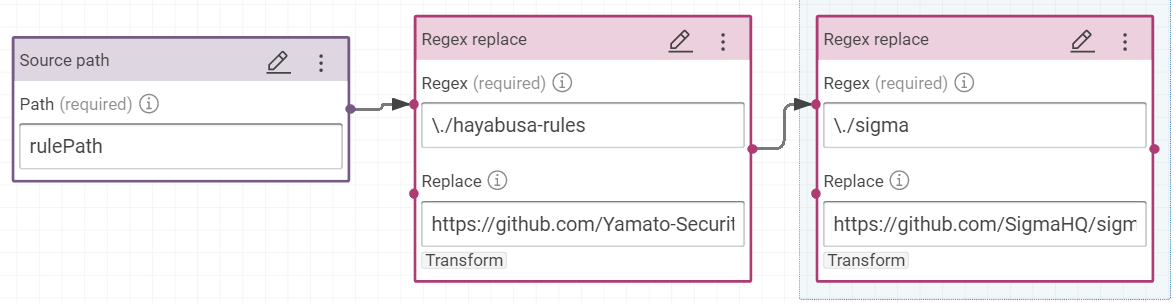
So the rulepath ./sigma/rules/windows/process_creation/proc_creation_win_bcdedit_boot_conf_tamper.yml becomes the link https://github.com/SigmaHQ/sigma/blob/master/rules/windows/process_creation/proc_creation_win_bcdedit_boot_conf_tamper.yml and ./hayabusa-rules/hayabusa/sysmon/Sysmon_15_Info_ADS-Created.ymlbecomes https://github.com/Yamato-Security/hayabusa-rules/blob/main/hayabusa/sysmon/Sysmon_11_Med_FileCreated_RuleAlert.yml
Tips
To test your transformer, you can use the tab “Transform execution”. Here, the knowledge graph will not be cleared after each workflow or execution to test your transformer because the option “clear graph before workflow” is disabled. However during the steps to build this transformer, you can enable tempory this option to see and test the final transformer. You need only to disable this option when your transformer is finished.
Success
Your example of rule exists now in your knowledge graph:
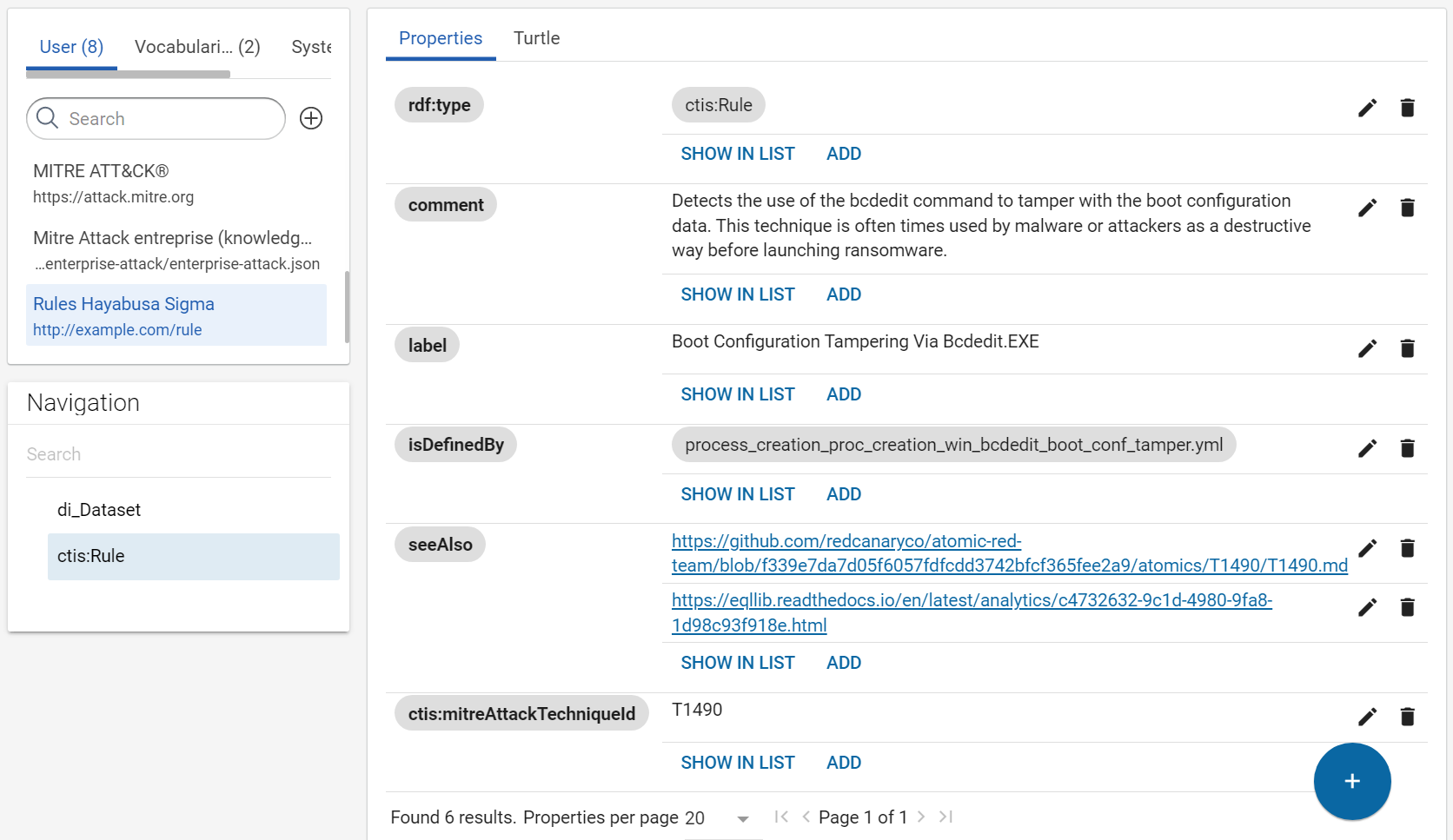
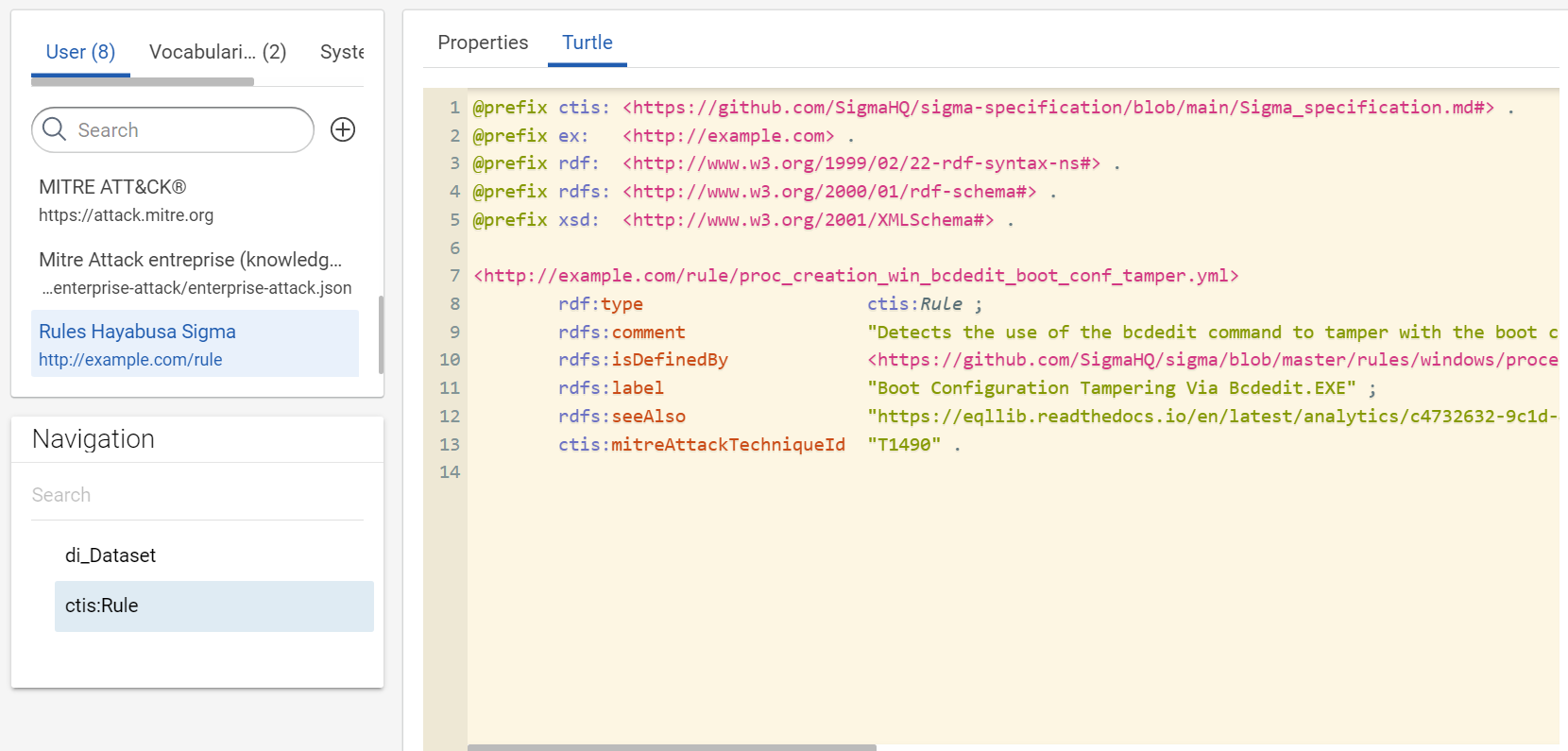
-
Make the workflow “Import rules” with one input

And don’t forget to allow the replacement of JSON dataset because it allows to replace this specific JSON by all other rules during the execution of this worflow.
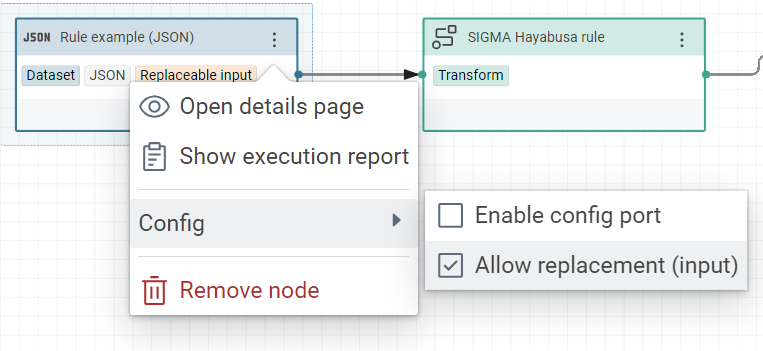
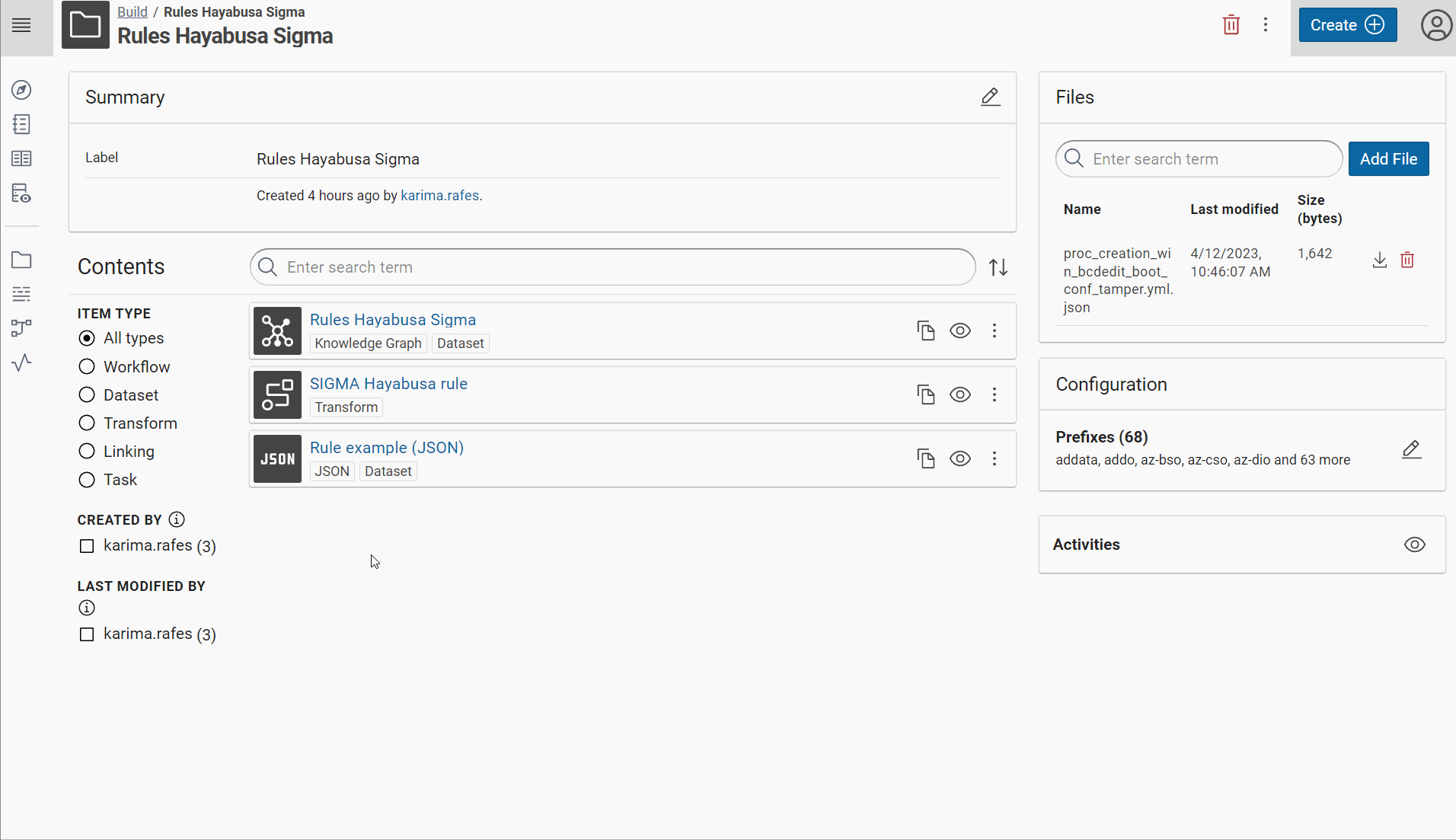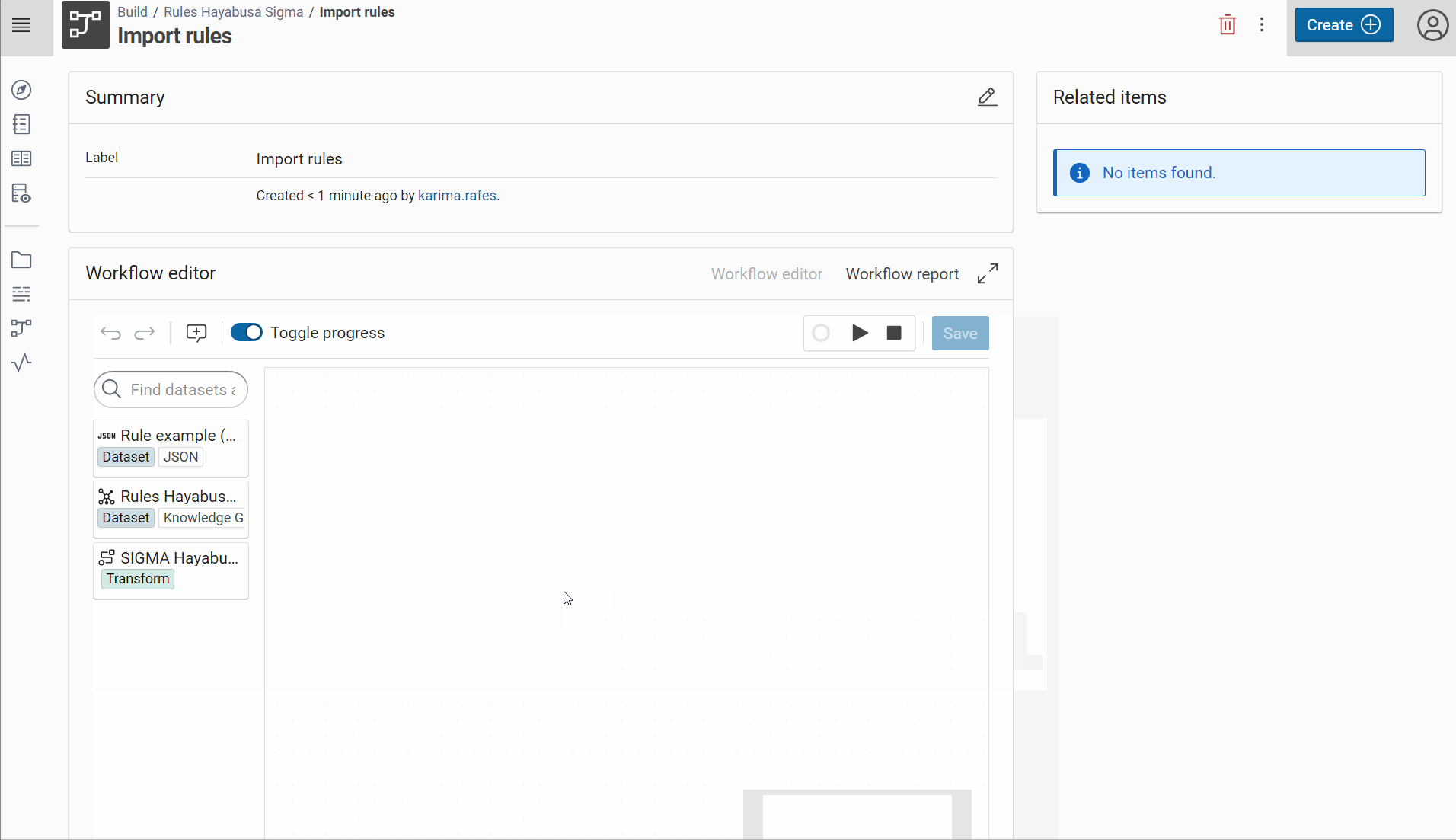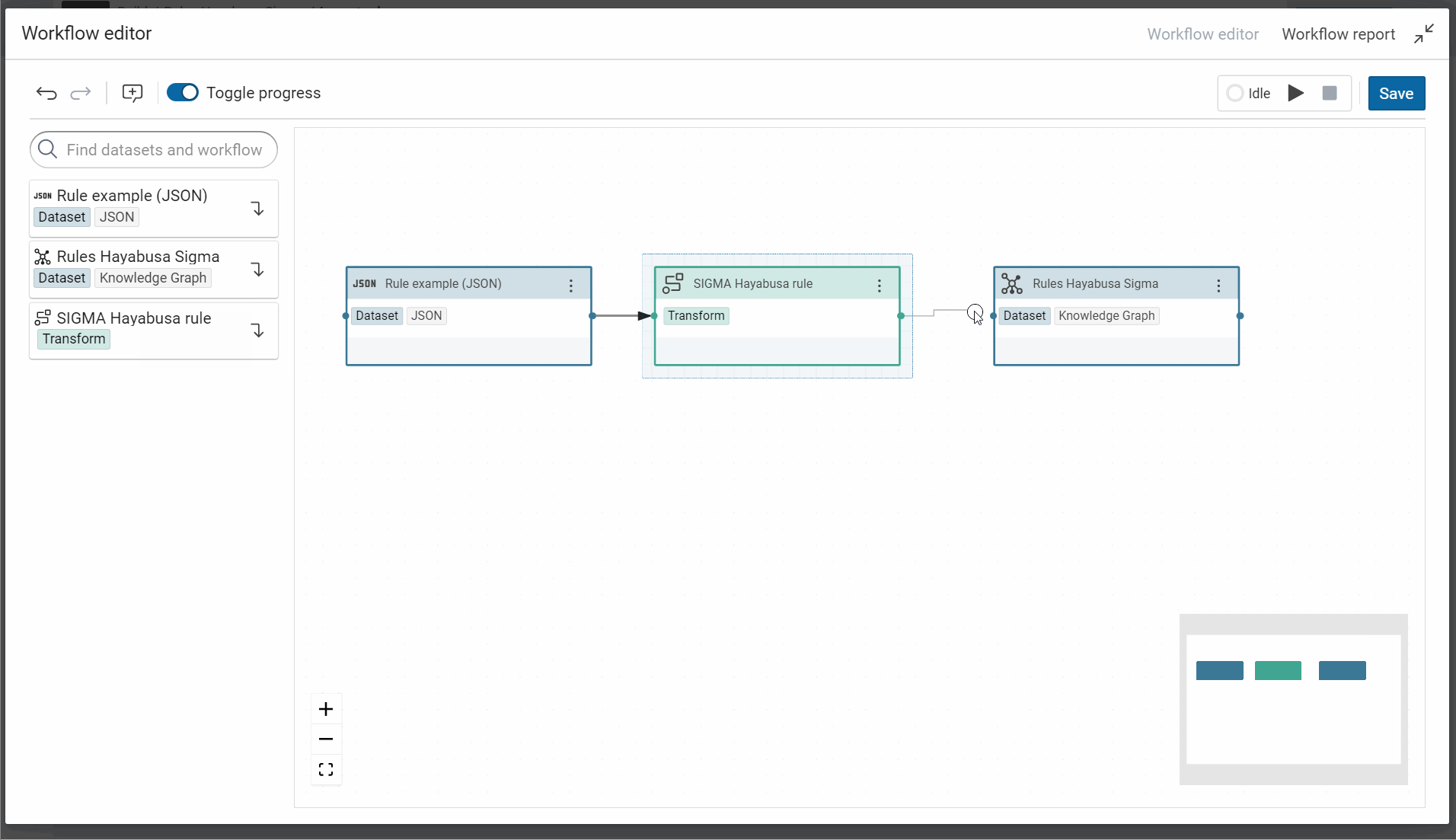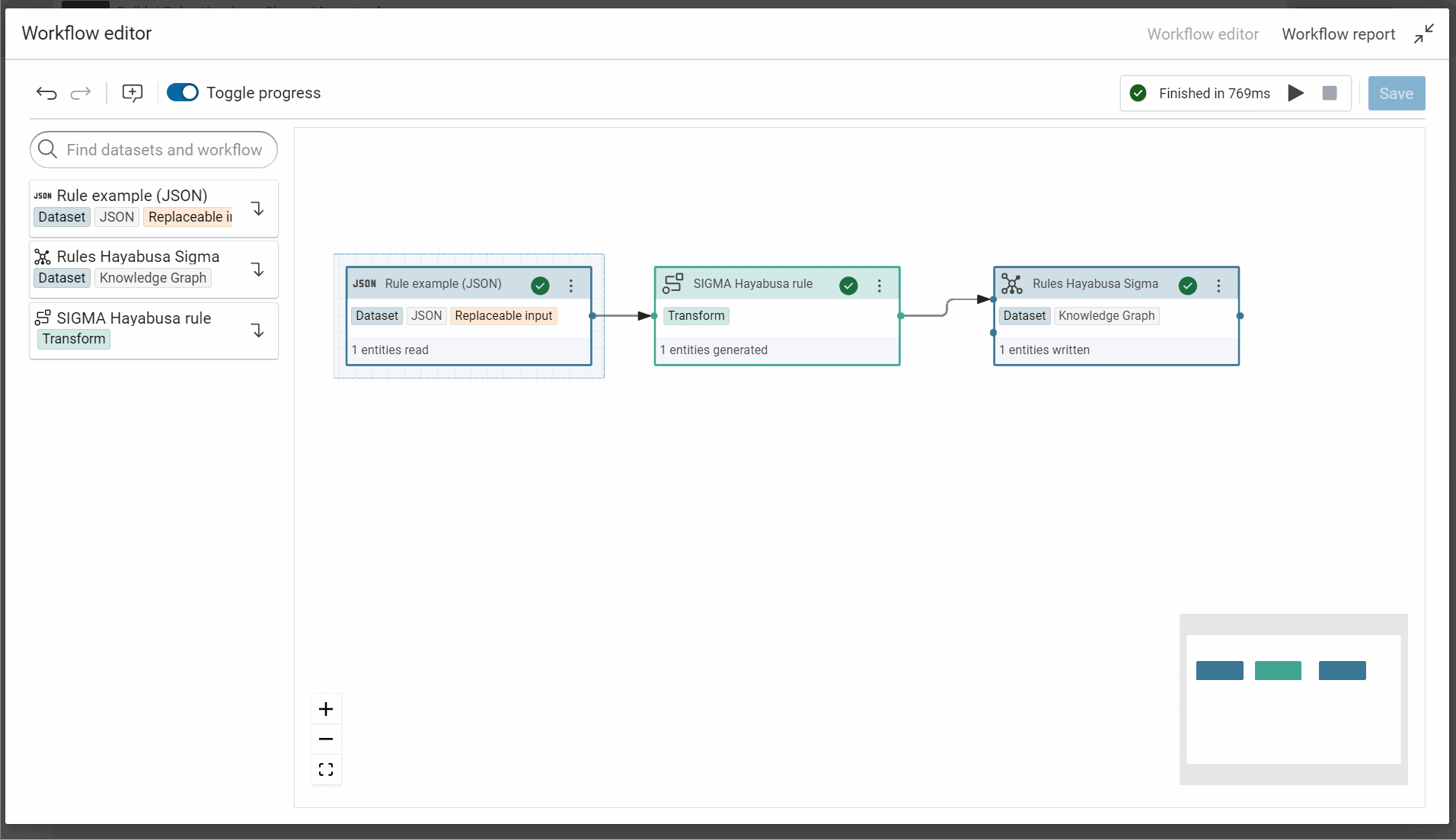
-
Copy the workflow ID
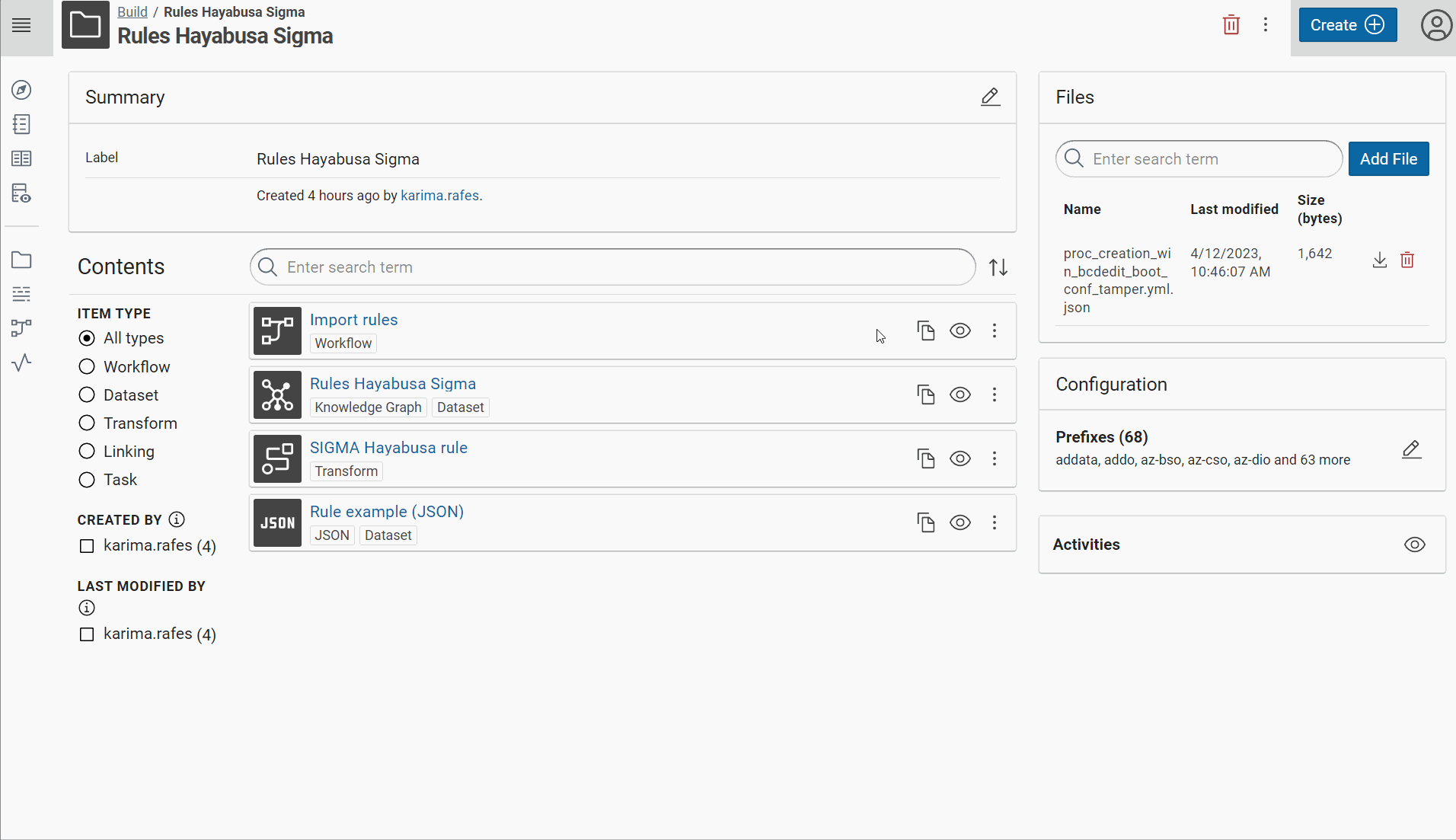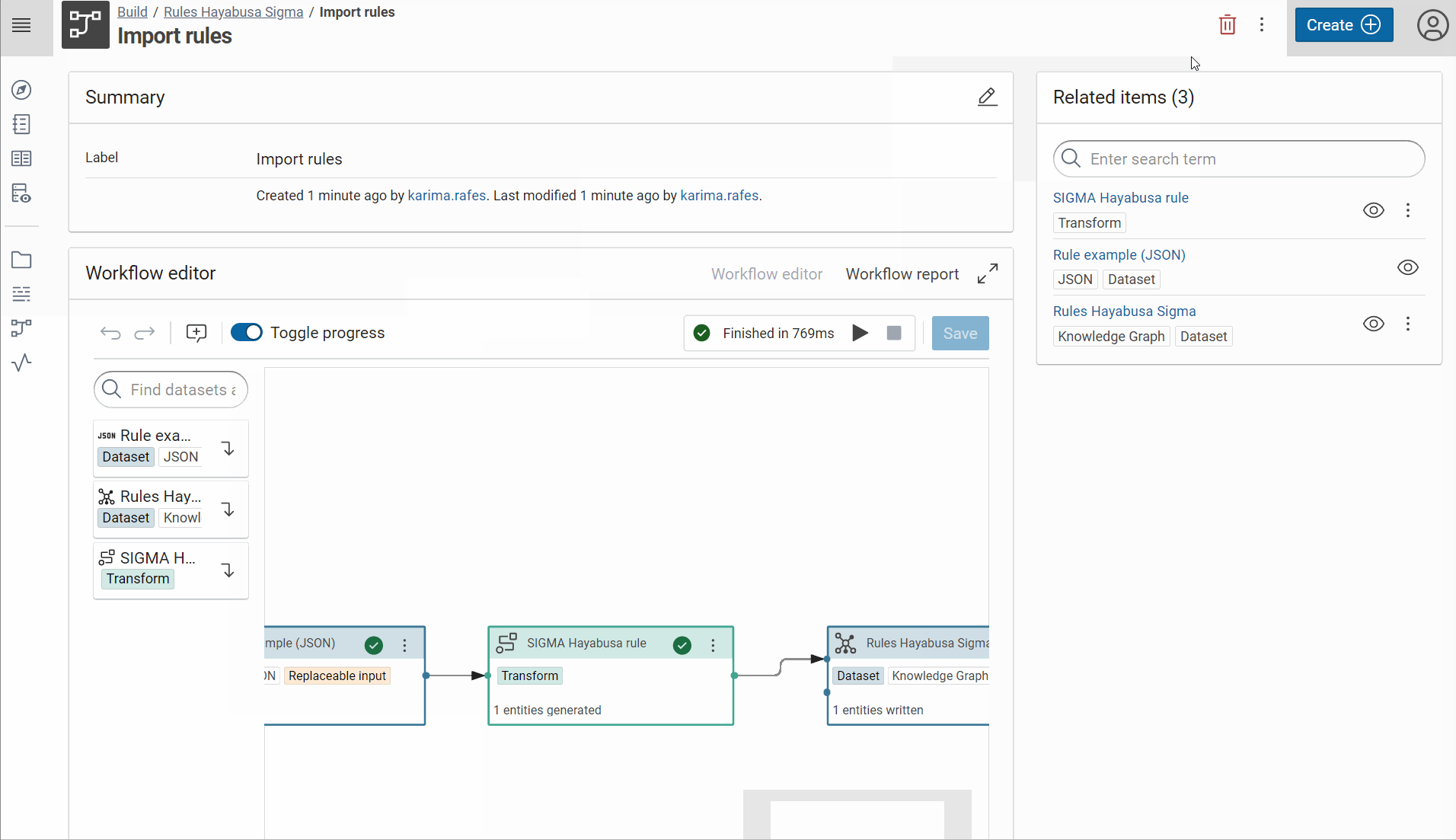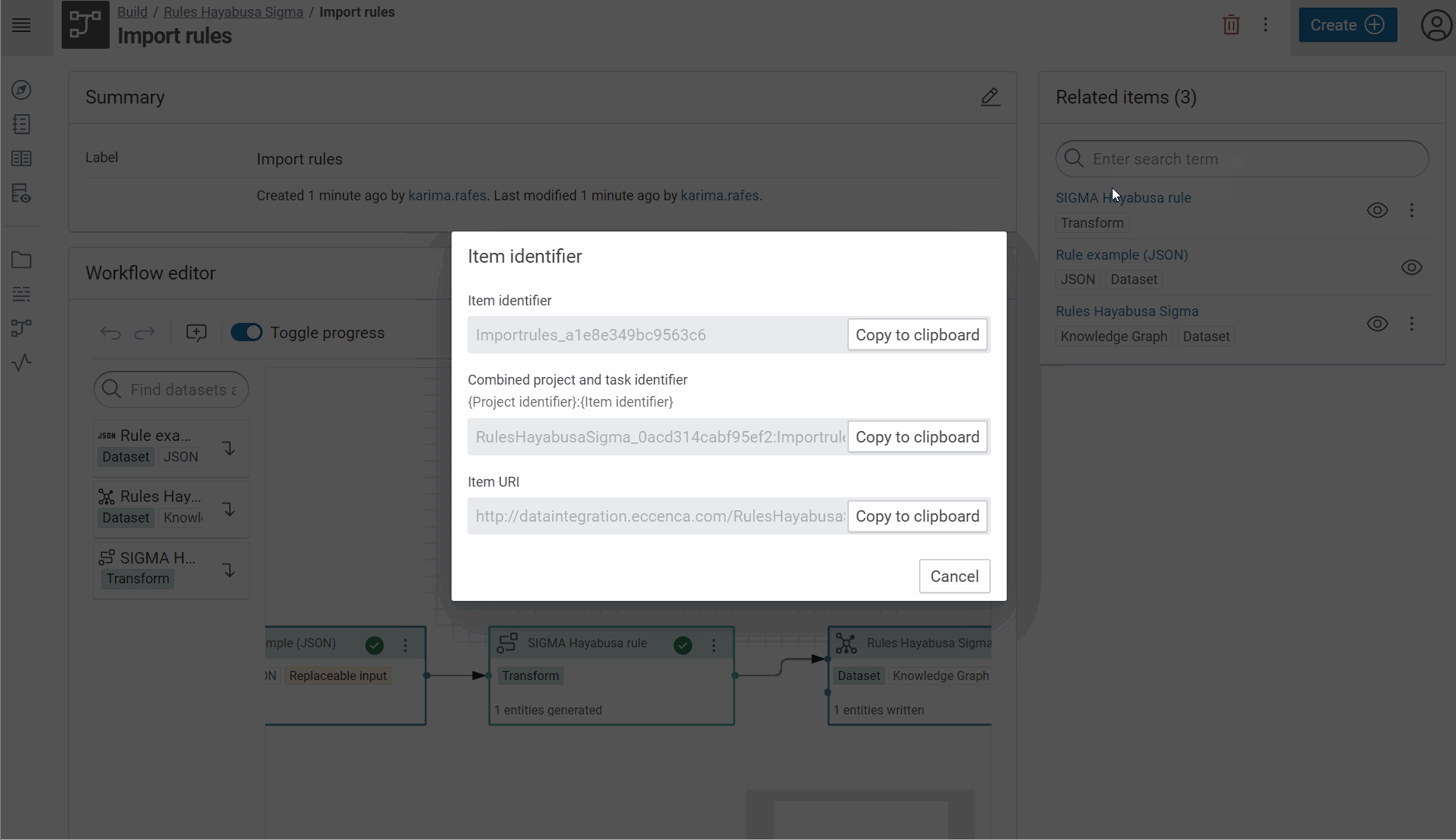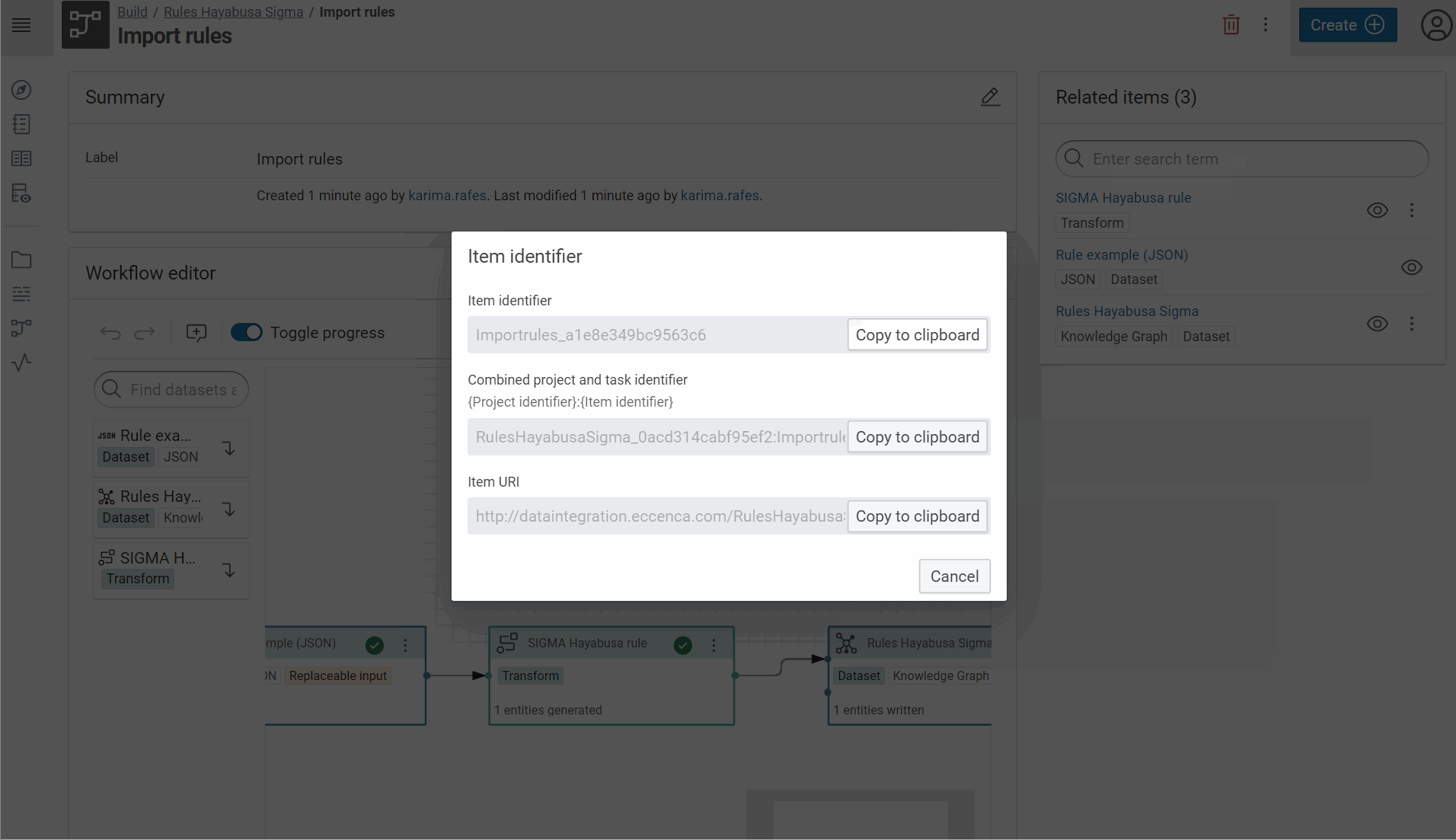
Success
In this example the ID of workflow is RulesHayabusaSigma_671e1f43d94bbc36:Importrules_6ccbc14b656c75c9
Apply the worflow to all files¤
We modify the first bash where we add the line to clear the knowledge graph before importing all rules via our worflow where we subtitute the JSON dataset in input by the rules’ files.
Tip
Don’t forget to replace the worflow ID and the final folder before using this bash.
Tip
CMEMC config file need to be correctly configurated before to execute this bash, like in the previous tutorial.
For example:
[johndo.eccenca.my]
CMEM_BASE_URI=https://johndo.eccenca.my/
OAUTH_GRANT_TYPE=password
OAUTH_CLIENT_ID=cmemc
OAUTH_USER=johndo@example.com
OAUTH_PASSWORD=XXXXXXXXX
Don’t forget to specify the config by default to use by CMEMC.
#!/bin/bash -x
output_dir_rules=/home/karima/datasets/rules
mkdir -p ${output_dir_rules}
cd ${output_dir_rules}
git clone --depth 1 https://github.com/Yamato-Security/hayabusa-rules
git clone --depth 1 https://github.com/SigmaHQ/sigma
for file in $(find . -name '*.yml'); do
[ -f "$file" ] || break
yq ".rulePath = \"${file}\"" -o=json $file > ${file}.json
done
cmemc graph delete http://example.com/rule
for file in $(find . -name '*.json'); do
[ -f "$file" ] || break
cmemc workflow io RulesHayabusaSigma_671e1f43d94bbc36:Importrules_6ccbc14b656c75c9 -i ${file}
done
We can test this script:
Conclusion¤
Here, we learnt how to generate a knowledge graph with files in input with Corporate Memory to prepare the worflow and cmemc to execute this worklow on all files.
Ressources¤
Tutorial: how to link Intrusion Detection Systems (IDS) to Open-Source INTelligence (OSINT)
Next chapter: Link IDS event to a knowledge graph in dashboards via queries
Previous chapter: Build a Knowledge Graph of MITRE ATT&CK® datasets